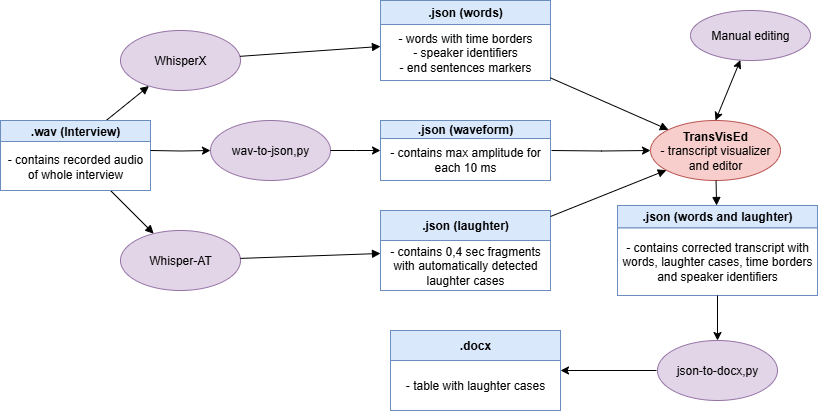
The Multimodal Digital Oral History project is developing a methodology and technical workflow for active engagement with the oral, aural and sonic affordances of both retro-digitised and born-digital oral history collections — across modalities including transcript, sound, waveform, spectrogram and metadata.
We are currently working on the detection of laughter in oral history interviews using AI tools, in combination with non-digital approaches. Laughter offers a compelling example of elements such as hesitations, vocal quirks and pacing typically omitted from manual transcripts.
Transcript Sound Waveform Metadata Modal flow
“ Beyond the transcript
The full communicative richness of oral testimony — laughter, hesitation, pacing, timbre — lives in the modalities that manual transcripts cannot capture.